Automatically Testing Your Content Security Policy Using Travis-CI and Headless Chrome Crawler
Saturday 28th July 2018
I have recently put together a Travis-CI build configuration that automatically tests your website for Content Security Policy violations. The configuration sets up a local copy of your site on a Travis-CI virtual machine with a CSP header set to send violation reports to a local reporting endpoint. The site is then crawled using Headless Chrome Crawler, which causes CSP violation reports to be generated where required. These are then displayed at the end of the build log.
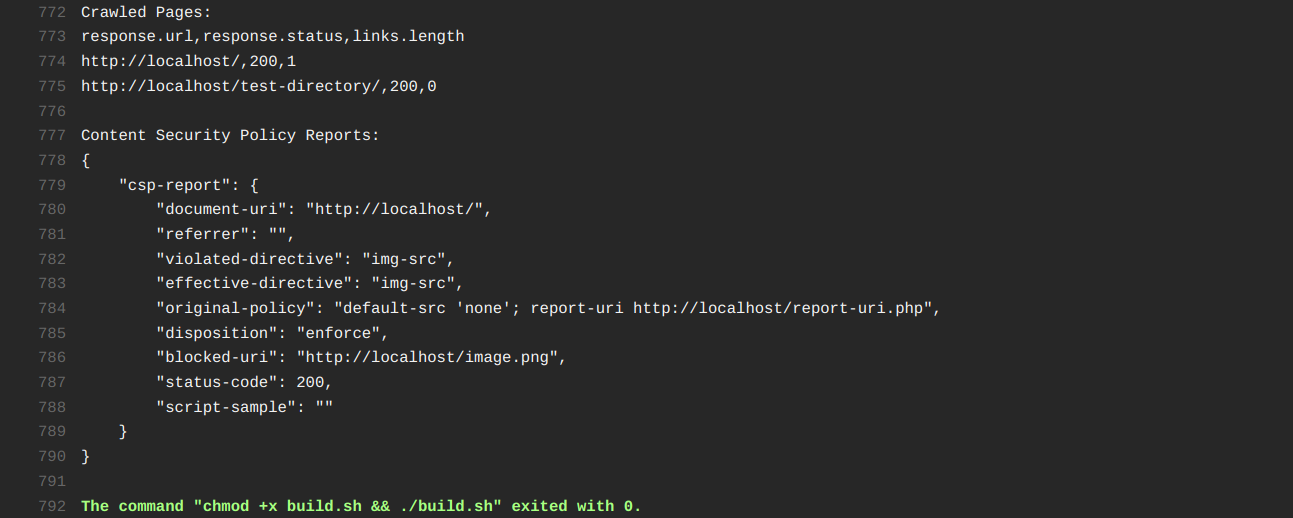
An example output showing a report for an image that was blocked by the Content Security Policy.
If you want to give this a go, all of the required files and instructions are available in the GitHub repository: https://github.com/jamieweb/
Skip to Section:
Automatically Testing Your CSP Using Travis-CI and Headless Chrome Crawler ┣━━ What is Travis-CI? ┣━━ Headless Chrome Crawler ┣━━ Apache Reverse Proxy ┣━━ CSP Violation Report Handler ┣━━ Report URI Integration ┗━━ Conclusion
What is Travis-CI?
Travis-CI is an online continuous integration service for projects hosted on GitHub.
It allows you to automatically test your code after every commit. These tests, known as 'builds', could be checking that your code compiles successfully, checking dependencies, checking compatibility, or in this case - checking a website for CSP violation reports.
Each build uses its own virtual machine on Google Compute Engine, or a container on Amazon EC2. The GCE VMs provide you will full root access to a complete system, while the EC2 containers are faster to boot.
Travis-CI is free for open-source projects.

Headless Chrome Crawler
Headless Chrome Crawler by yujiosaka is an open source web crawler powered by Headless Chrome.
Headless Chrome is a feature of the Google Chrome/Chromium browsers that allow you to run them in a headless environment. This essentially means that you can utilise the full functionality of a desktop web browser, but in a command-line environment. It's essentially a 'no GUI' mode, and comes in extremely useful for automated testing, page rendering, etc.
The reason that this comes in so useful for a crawler is that it allows the crawler to see the website as though it is an actual user using a proper desktop web browser. Many websites these days use frameworks such as AngularJS or React, which means that much of the content on the screen is actually written to the DOM using JavaScript, rather than simply being raw HTML. This means that using tools such as curl or wget to crawl websites will often result in an incomplete output, as the JavaScript has not run to populate the page with its content.
One of the other reasons for me using Headless Chrome Crawler for this project is that Headless Chrome will send Content Security Policy violation reports, which are exaclty what is needed to help check the compatibility of a CSP properly.
Apache Reverse Proxy
In this build environment, the PHP built-in development server (php -S) is used to host the local website.
The reason for using this and not just raw Apache is that it is not easy to get the latest version of mod_php set up and running in the Travis-CI environment. According to the Travis-CI documentation, mod_php is not officially supported and you should use php_fpm instead.
In order to avoid these possible complications, the PHP built-in development server works fine. However, with this web server it is not possible to set headers on a global basis - it's only possible to set them in the code itself using the PHP header() function.
In order to get around this, I am using Apache as a reverse proxy for the PHP built-in server. The Apache server can set the Content-Security-Policy header, as well as proxy all of the traffic relatively seamlessly. The configuration is pretty simple too:
ProxyPass "/" "http://localhost:8080/" ProxyPassReverse "/" "http://localhost:8080/"
For a website using a content management system or framework, this solution probably wouldn't work, as the site depends on many web server configurations and other factors that the PHP built-in server cannot handle. I think that this Travis-CI build environment configuration could be easily modified in order to handle a website like this if required.
Another alternative would be to not host a local copy of the website at all, and just scrape the real one or a development/staging version that is accessible over the internet.
CSP Violation Report Handler
In order to receive the locally generated CSP violation reports, there needs to be a report handler somewhere on the server.
During a build, the raw JSON reports are handled by report-uri.php. This file is not actually included in the repository by itself, instead it is created by a command in the .travis.yml file:
printf "<?php \$report = json_decode(filter_var(file_get_contents('php://input'), FILTER_DEFAULT, FILTER_FLAG_STRIP_LOW | FILTER_FLAG_STRIP_HIGH)); if(json_last_error() !== JSON_ERROR_NONE) { exit(); } elseif((in_array(\$report->{'csp-report'}->{'blocked-uri'}, array_map('trim', file('blocked-uri-exclusions.txt')))) || (in_array(\$report->{'csp-report'}->{'document-uri'}, array_map('trim', file('document-uri-exclusions.txt'))))) { exit(); } else { file_put_contents('csp-reports.txt', json_encode(\$report, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES) . \"\\\\n\\\\n\", FILE_APPEND); } ?>" > report-uri.php
The reason that this file is generated using printf and not just included in the repository is that the code is not suitable for internet-facing use. Because of this, I don't want it to be accidentally exposed to the internet on someone's web server.
This is because the program is designed to output to a file that is then printed to the shell at the end of the build. Attacks such as cross-site scripting (XSS) are not possible here as the output is never actually parsed by a web browser. PHP functions such as escapeshellcmd() are also no use here as the output is not being used to construct a shell command.
The only real risk is in actually displaying the untrusted data, as explained here. In order to help mitigate this risk, I have used filter_var with the flags FILTER_FLAG_STRIP_LOW and FILTER_FLAG_STRIP_HIGH, which will attempt to strip out characters with an ASCII value <32 and >127. Even if a successful attack were to take place, this code is running on a remote virtual machine/container that was specifcally created for your build - the VM/container will be destroyed as soon as the build is finished.
If you pretty-print the code, it looks like the following:
<?php $report = json_decode(filter_var(file_get_contents('php://input'), FILTER_DEFAULT, FILTER_FLAG_STRIP_LOW | FILTER_FLAG_STRIP_HIGH));
if(json_last_error() !== JSON_ERROR_NONE) {
exit();
} elseif((in_array($report->{'csp-report'}->{'blocked-uri'}, array_map('trim', file('blocked-uri-exclusions.txt')))) || (in_array($report->{'csp-report'}->{'document-uri'}, array_map('trim', file('document-uri-exclusions.txt'))))) {
exit();
} else {
file_put_contents('csp-reports.txt', json_encode($report, JSON_PRETTY_PRINT | JSON_UNESCAPED_SLASHES) . "\n\n", FILE_APPEND);
} ?>
The code parses the raw JSON input. If it is valid JSON, the blocked-uri and document-uri values are checked against blocked-uri-exclusions.txt and document-uri-exclusions.txt respectively, which are optional configuration files that can be used to exclude certain reports, such as false positives.
If the report is not excluded, it is appended to csp-reports.txt, ready to be printed out at the end of the build.
Report URI Integration
My original plan for this project was to integrate it with Report URI, so that the reports could be viewed and managed on an online dashboard.
However, this unfortunately turned out not to be ideal as there isn't an easy way to determine which reports came from which build. It is possible to sort them by time, although if there are multiple builds happening one after another or close together, it isn't easy to tell which reports came from which build.
This is not the fault of Report URI though - I'm trying to use the service for something that it wasn't designed for, so it's definitely not to blame. For a more standard use of CSP reporting, Report URI is a fantastic service and I highly recommend it.
Edit 30th Jul 2018 @ 9:41pm: Shortly after publishing this blog post, Scott Helme (the creator of Report URI) tweeted me with a possible solution to the problem. Scott suggested running the local site using a subdomain containing the Travis-CI build number, so that each time the build runs and it is crawled, the reports are distinguishable from all of the previous builds.
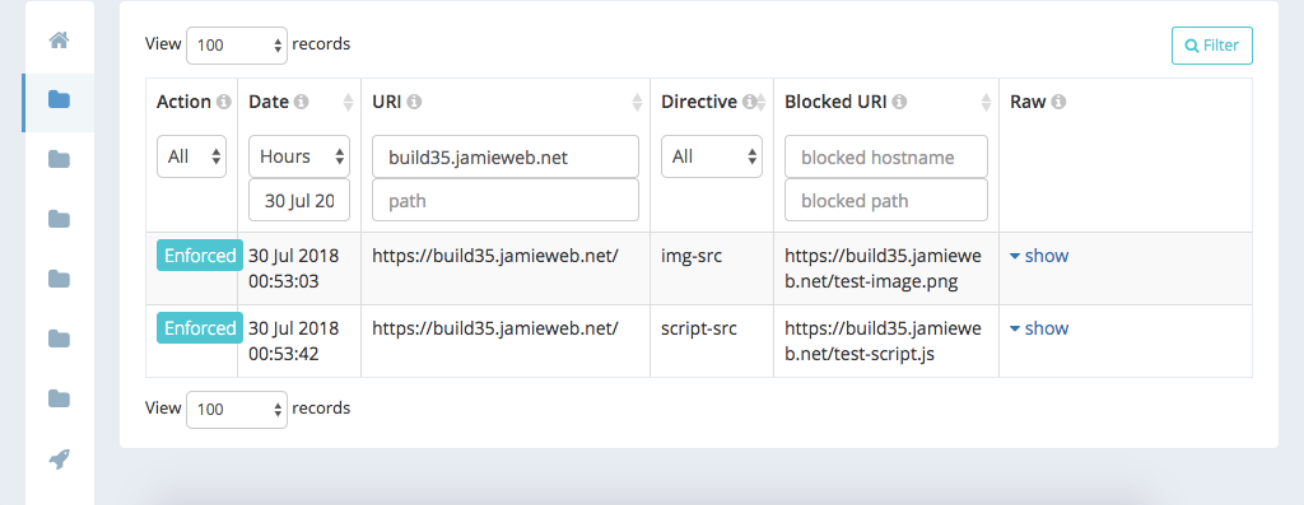
I implemented this in the Travis-CI build configuration by using /etc/hosts to set up a locally resolvable subdomain that contains the build number (which can be gotten from a Travis-CI environment variable). The crawler is then set to crawl this subdomain, which results in the CSP violation reports containing the build number subdomain. These can then be easily filtered from within the Report URI interface.
One of the challenges with this setup is HSTS Preload. Since my domain (jamieweb.net) is HSTS Preloaded, the crawler will only allow the connection to the local site over HTTPS. In order to resolve this, a self-signed TLS certificate is generated during the build and added to the nssdb, which is the trusted certificate authority list used by Chrome/Chromium on Linux. Apache is also configured to serve this certificate, meaning that the crawler is able to crawl the site without any HTTPS errors.
If you wish to integrate this with your Report URI account, simply set your Report URI reporting subdomain in the environment variables at the top of the .travis.yml file.
Thanks again to Scott for his help!
I do think it would be interesting for Report URI to integrate some form of automated CSP testing in to their service. They already offer the CSP wizard service which is used to help construct and maintain a CSP using reports from real users' browsers, however I'm talking about something where they crawl your site on your behalf and output the reports just from that particular crawl. This feature would be useful for testing your CSP across your entire website after making a change to the policy or modifying content on your site. Of course any violations should be picked up anyway by the reports coming from your users, however been able to set off a crawl and view the reports from it would help to identify any issues as a result of the changes much quicker. Every users' browser is different though, which means that different violations may occur for real users than those that occur in a sterile crawler environment.
Conclusion
I've set this system up for JamieWeb, so every time I commit to the GitHub repository, the Travis-CI build is automatically run and checks for any CSP violation reports that are generated.
I have an extremely tight Content Security Policy on this site, and I even use web server configurations (Apache Files directives) in order to set a different policy for specific pages that require things to be let through (such as the Exploitable Web Content Blocking Test). This Travis-CI build configuration will help me to ensure that no inline styling from site development is accidentally left in (this should never be in production), as well as to help spot any other CSP violations that happen for any other reason.
Currently this setup is designed to work with PHP websites, however it could be easily adapted to work with other types of website too. Feel free to fork the repository if you wish to help get this set up and working for a different type of website backend.
I have no affiliation with Travis-CI, Headless Chrome Crawler or Report URI.